
티스토리 뷰
※공부하고 이해한 내용을 나름대로 정리한 포스팅입니다.
올바르지 않은 내용이 있을 가능성도 있습니다.
Ensemble(앙상블)기법이란?_2/2
지난 포스팅
: 학습 모델의 오류(편향과 분산)와 그 해결
2019/06/15 - [데이터분석/데이터 분석 개념] - ToDo 머신러닝#1_Ensemble_1/2; 학습 모델 오류 이해
■ Ensemble기법 유형
1. Bagging(배깅)
2. Boosting(부스팅)

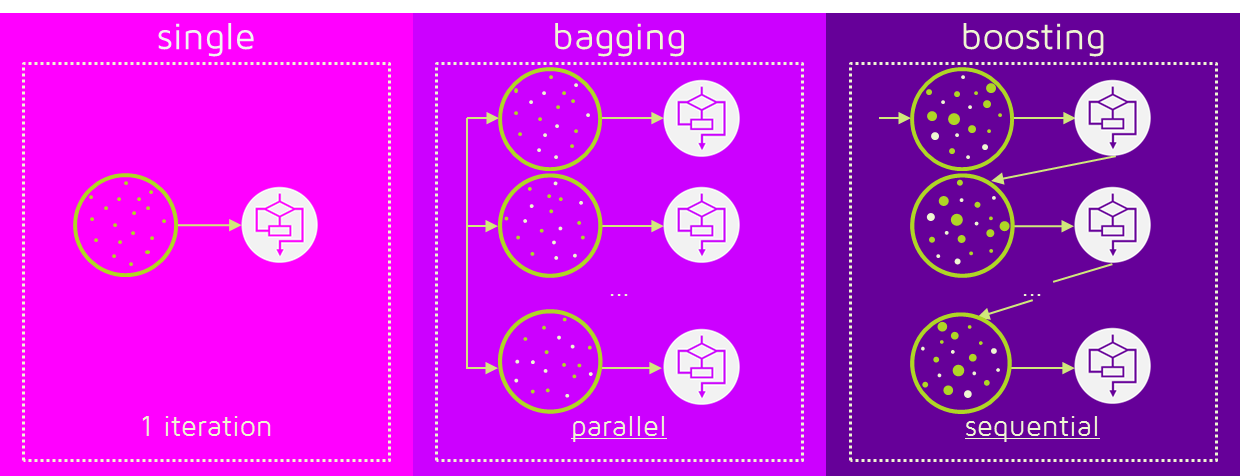
1. Bagging
Bagging은 Bootstrap Aggregating의 약어로,
통계학에서의 Bootstrap은
한 표본을 여러 데이터셋으로 다시 샘플링(Resampling)하는 것을 의미하고
Aggregating은 집계를 의미하여,
쉽게 말해, 한 표본을 resampling하여 집계하는 기법입니다.
Bagging은 특히 High Variance의 경우 적합한데,
Resampling된 데이터셋들에 적용된 각각의 모델들의 예측값은 서로 다르고,
그 다름(High Variance)을 해결하기 위해,
각기 다른 예측값들을 가지는 데이터 셋(약한 분류기=weak learner)*들을 집계하여
하나의 데이터 셋(강한 분류기=stong learner)를 생성하여
Variance를 낮춥니다.
*참고
어떤 설명에서는 bagging과 boosting모두
weak learner들을 결합해 storng learner을 생성하는 것이라고 나타내지만,
특히 bagging에 대한 다른 설명에서는
weak learner대신 base learner라는 표현을 사용합니다.
개인적으로는, bagging에서는 각 모델의 오류(weakness=residual)를 고려하지 않으므로
base learner가 적합해보입니다.
Resampling시,
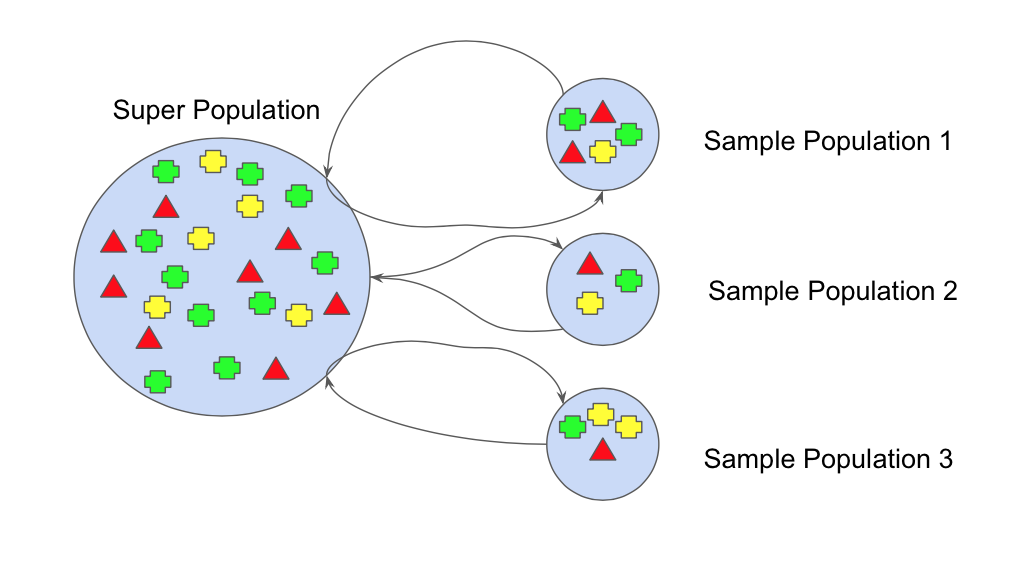
무작위로 샘플을 구성하며,
각 모델들의 예측값이 서로 영향을 주지 않아
서로 독립적입니다.(=병렬Parallel 앙상블)
집계는, 분석의 목적이
Classification(분류)일 경우 과반수투표(Vote),
Regression(회귀)일 경우 평균치(Average)를 사용합니다.
대표적 예로는
traing과정에서 생성되는 여러 Decision Tree(의사결정나무=base learner)들을
평균 혹은 과반수투표를
하나의 숲(강한 분류기)를 생성하는
Random Forest(랜덤포레스트)가 있습니다.
2. Boosting
boosting은 bagging의 변형으로,
각 모델에 데이터를 샘플링할 때,
전 모델의 오류(=잔차 residual)*에 가중치를 부여하는 방법으로
다음 모델에서 오류를 해결하고자 합니다.
(학원이나 학교로 따지면, 열등생 집중보충교육과 비슷,,)
*참고
잔차란, 예측 후 남은 값, 즉 정답과 다른 값(=오류)을 말합니다.

Box1에서 파란 + 3개의 예측에 오류가 발생하여,
Box2에서 그 파란 +에 가중치를 부여하며, 빨간 - 3개에도 오류가 발생해,
Box3에서 그 빨간 -에 가중치를 부여하여
Box4에서 정답에 가까운 예측이 완성됨을 알 수 있습니다.
그렇기에 bagging과 달리
boosting은 High Bias의 경우, 그 Bias를 낮추는 것에 적합합니다.
또한, 무작위로 샘플을 구성하지만,
각 모델의 예측값이 서로 영향을 주므로
순차적(Sequential)앙상블 기법이라고 할 수 있습니다.
(= 잔차를 순차적으로 해결하므로 Residual Fitting의 하나라고도 볼 수 있음)
그리고, Boosting은 가중치 부여 방식에 따라
여러 기법으로 나뉩니다.
그리고 이 기법들이 바로
Kaggle 상위 랭킹 커널에서 사용되는
Adaboost, GBM, LightGBM, Catboost 등을 말합니다.
여기선 Adaboost와 GBM을 우선적으로 이해해보려고 합니다.
2.1 AdaBoost(아다부스트)
Adaboost는 Adaptive Boosting의 약자로,
여기서 Adaptive은,
전 모델의 오류에 가중치를 부여해 다음 모델에서 오류를 해결하는 방식이
모든 모델에 적용될 때까지 반복하여
Weak learner들이 오류 해결 알고리즘에 "적응"되는 것을 의미합니다.
위의 Boosting 설명에서 크게 벗어나지 않는,
즉 Boosting의 가장 기본적 알고리즘이라고 할 수 있습니다.
2.2 GBM(Gradient Boosting Algorithms)
그렇다면 Gradient Boosting은 무엇일까요?
이를 이해하기 위해
우선 Gradient Descent(경사 하강법)을 이해할 필요가 있습니다.
Gradient Descent은,
함수의 기울기를 낮은 값으로 점점 이동시켜,
극 값에 이르도록 하는 방법입니다.

손실 함수에서 손실 값을 줄이는 것에 사용되는
대표적 기법으로, 이 때 손실은,
예측값 중 정답과 다른 값들을 의미한다고 할 수 있습니다.

손실 함수에서 기울기는 벡터, 즉 크기와 방향을 지니며
손실을 최소화하는 지점(즉, 극 값)으로 향하기 위해
시작점의 기울기에
반대방향(음의 기울기=Negative Gradient)*을 취하고,
크기를 가늠해 다음 지점으로 향하는 방법을 반복하여
결국 손실함수의 극 값으로 향하게 합니다.
*참고
손실함수의 모든 기울기는
기본적으로 손실이 최대화되는 방향으로 향하므로,
그 반대 방향을 취해주어야 합니다.
GBM도 Adaboost와 비슷하지만
전 모델의 오류에 가중치를 부여하는 과정에서
Gradient Descent를 통해 최적의 파라미터를 찾는다는 점에서
차이점이 발생합니다.
(그리고 이는 지난 포스팅에서도 다뤘듯,
Total error의 최소점을 찾는 것과도 이어집니다.)
이렇게 머신러닝에서 발생하는
학습 모델의 오류 2가지; Bias와 Variance,
그리고 이를 해결하기 위한 Ensemble기법과
그 대표적인 방법 2가지; Bagging과 Boosting
을 이해할 수 있었습니다.
참고
1. https://www.slideshare.net/freepsw/boosting-bagging-vs-boosting
2. https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent?hl=ko
3. https://becominghuman.ai/ensemble-learning-bagging-and-boosting-d20f38be9b1e
'데이터분석 > 알고리즘' 카테고리의 다른 글
| ToDo 머신러닝#1_Ensemble_1/2; 학습 모델 오류 이해 (0) | 2019.06.17 |
|---|
- Total
- Today
- Yesterday
- 쿠싱
- 상관관계
- 분산
- 조건부확률
- SQL
- Python
- 중앙값
- neural network
- 분당서울대병원
- 프로그래머스
- 쿠싱증후군
- 평균
- counter
- 통계
- 군고구마
- 뇌하수체선종
- hash
- random forest
- 확률분포
- 상대도수
- 뇌하수체
- leatcode
- 사분위수
- 코딩테스트
- Lambda
- programmers
- 파이썬
- 힙
- 확률
- TensorFlow
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |